
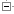
Orthologue alignment
The cDNA or protein alignment between two orthologuous sequences is shown in CLUSTALW format. For both cDNAs and proteins, this consists of one sequence on top of the other, each labelled with the Ensembl protein IDs, and a track underneath indicating conservation between the sequences.
For cDNA alignments, the conservation codes are:
*when nucleotides are identical:
spacewhen nucleotides are different
For protein alignments, the conservation codes are:
*when amino acids are identical
:when amino acids are different but the function is conserved
.when amino acids are different but the function is semi-conserved.
spacewhen amino acids are different and there is no conservation of function.
Dashes in the sequence (for both nucleotides and amino acids) indicate gaps in the alignment.
In this view, we also provide the Ensembl stable IDs for the orthologous pair of genes and proteins, alongside the protein length, gene location, the % identity and % coverage.
% identity is the number of identical sites (amino acids or nucleotides) between two sequences in the alignment.
% coverage is the number of sites (amino acids or nucleotides) covered by the alignment (insertions and deletions are not included in the calculation).
For each pair of orthologs with different protein lengths, there will be two numbers for % identity, and two numbers for % coverage, as both values depend on the protein length.
See the BRCA2 homologous in human and anole lizard for an example.

When the human protein ENSP00000439902 (longer protein in pink) is aligned to the lizard protein ENSACAP00000004459 (shorter fragment in blue), only 18% of the amino acids are identical to the lizard protein. The human protein is much longer and extends far beyond the lizard protein. In this same diagram, 51% of the amino acids in the lizard protein are identical to sequence in the human protein.
In the same way, the % coverage of the human protein by the lizard protein is 35%. However, 97% of the shorter, lizard protein is covered by the human protein.